Synopsis
I joined up with a few friends in my senior design class to tackle an interesting project. We chose to detect pirated videos for our client, Telestream. Having taken Computer Vision at our college, we had enough of a background in feature analysis and image comparison to create a solution.
The functional requirement was to use SIFT to determine whether a query video was copied, in-part or in-whole, from a pre-constructed database. Our client suggested that we use C++. We would create two command line applications, one for adding videos to a database, and one for querying videos against that database.
The non-functional requirement of our system was that we had to be robust to attacks–video transformations–that pirates could use to defeat our detection. The attacks that we tested against were:
- Scale
- Rotate
- Cropping
- Mirror
- Picture in picture
- Frame rate changes
Using SIFT
We picked up the project in January, 2020. At the time, the SIFT algorithm was patented by David G. Lowe, so our client wanted us to create a custom implementation of SIFT. There are multiple open-source implementations of SIFT. However, the patent protects any commercial use of the algorithm, which we hoped would expire before our project was completed. It expired in March 2020.
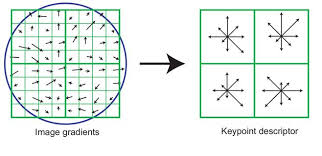
SIFT stands for scale invariant feature transform. Reference points are detected in an image using a difference-of-gaussian filter. These keypoints are then passed to a pipeline that extracts a histogram of gradient orientations surrounding each keypoint, forming a 128 feature vector.
Using OpenCV
OpenCV contains an implementation of the SIFT algorithm, however it is marked as nonfree and is not built with most distributions of OpenCV. We would have to build from source to get the nonfree implementation. This created an immediate problem for setting up our environments on our 4 separate development computers. We were also using Windows but targeting Linux for our project, so we had to figure out a way to provision 4 separate virtual machines, plus a continous integration environment to run our tests.
I decided to provide a shell script that would automatically configure, build and install a distribution of OpenCV for Ubuntu (we all used Ubuntu, including GitHub CI). I used this provisioning script in Vagrant to provide a one-step setup process for the project. For GitHub CI, I split the build and install steps of OpenCV so I could cache the build artifacts in GitHub, then pull it down to install for every container instance that ran our tests.
Architecture
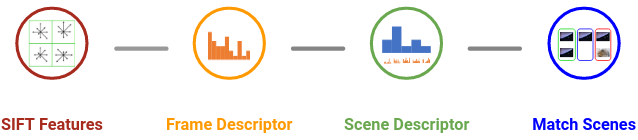
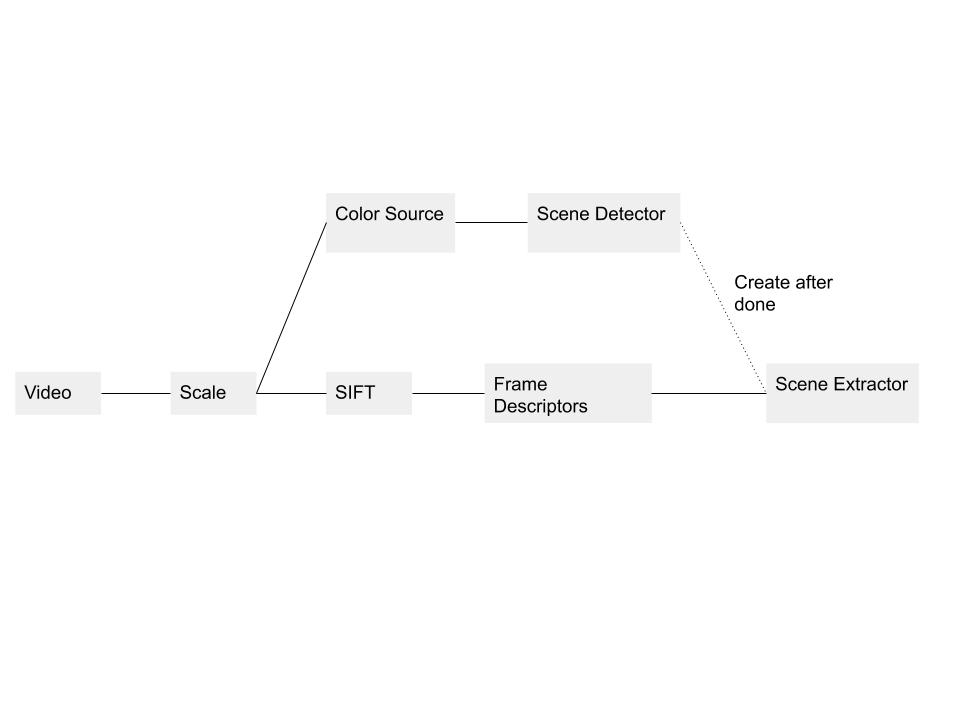
At a high level, our solution first extracts SIFT features from a video frame, creates a descriptor for that frame using a bag-of-words method, detects scenes from the video, creates a descriptor from these scenes using a bag-of-words on entire frames. We then pass this final sequence of scene descriptors to our sequence matching algorithm, that compares the query video to videos in the database.
Database Creation
Our initial prototype extracted the SIFT features from each frame in a video and stored them by index in a folder with the video’s name. We calculated a bag of words vocabulary over all of the frames, then used that to calculate a frame descriptor for each frame of the database video and query video. We took the cosine distance between sequential frames of the query and database video and used the average distance to calculate the match.
This approach, while naive, suggested to us that we should sequentially load and save videos to the database in some sort of filesystem. The other option for a database is to use a NV-tree to run a nearest-neighbors search for each frame in the query video. While this would make the queries faster, it is harder to reason about the quality of a match, and the ability to match a sequence of video.
We transitioned to using Smith-Waterman to do sequence comparison over frames, and soon realized that computing each bag-of-words descriptor at runtime was too slow. We decided to compare scenes instead of frames as any video will have many fewer scenes than frames.
We tried a number of methods for scene detection, but we ended up with comparing the color histograms for sequential frames, sorting these distances for a whole video, and then cutting scenes based on a threshold of scene length.
Roughly the database would be serialized like this:
database/
config.txt
FrameVocab.mat
SceneVocab.mat
video/
metadata.txt
frames/
...
scenes/
...
The config.txt file describes the input arguments that were last used in the add utility. This allows us to process the query videos with the same parameters as the database videos. The metadata.txt file stores the hash of FrameVocab.mat and SceneVocab.mat that was used to create the video, as well as provides a count of the number of frames and scenes. This is used to determine if the video is consistent with global database state.
I chose an object oriented approach for my first implementation. A simplified version of the initial OOP structure is here:
struct Frame {
cv::Mat siftDescriptor, frameDescriptor;
};
struct Scene {
int startFrameIdx, endFrameIdx;
cv::Mat descriptor;
};
class IVideo {
string name;
public:
virtual vector<Frame> getFrames() const = 0;
virtual vector<Scene> getScenes() const = 0;
};
class IDatabase {
public:
virtual void saveVideo(const IVideo& video) = 0;
virtual unique_ptr<IVideo> loadVideo(string name) = 0;
virtual vector<string> listVideos() const = 0;
};
class FileDatabase : public IDatabase {
...
};
class InputVideo {
// video loaded from file
};
template<typename Base>
class VideoAdapter : public IVideo {
...
vector<Scene> getScenes() {}
}; // adapter that satisfies IVideo interface with no scenes
class DatabaseVideo : public IVideo {
// video loaded from database
};
The rest of the codebase would work with the I* interface classes. There were a couple problems with this design:
- There’s only one or two implementations of each interface in the project
- Interface semantics in C++ (return pointers and take references) are verbose
- IDatabase looks like a repository pattern for videos
- IVideo is too abstract for
IDatabase::saveVideo - The user of
IDatabase::loadVideodoesn’t know if the loaded video has scene descriptors and frame descriptors
The second to last point involves a lot of complexity. Saving a video involves a few steps: 1. Load SIFT descriptors from video 2. Check if Frame Vocabulary exists 3. Proceed to calculate bag-of-words for each frame 4. Calculate scenes for video 5. Check if Scene Vocabulary exists 6. Calculate scene descriptors. 4. and 1. can take place independently of one another. The database can also be left in a partial state if it is interrupted or the dependencies for any step are not satisfied.
A video can be loaded to help construct a scene vocabulary or to perform sequence matching against a query video. Each of these steps has different requirements of the partial state a video is in, or how many descriptors have been calculated. I decided to initialize the database with a load strategy that would force the database to attempt to calculate, or preload, the required information. In hindsight, I should have written different functions into the interface for different load scenarios as this is easier to reason about.
Data Pipeline Architecture
A problem hidden within this system is that the scenes and frames are passed around as arrays. This was feasible initially with our 10 second videos we would test with, but would quickly overrun available memory if we were to process longer videos. Thus we would need to switch to a streams based implementation of our pipeline.
I created a custom iterator interface to help implement the stream:
template<typename T>
class ICusor {
public:
virtual optional<T> read() = 0;
virtual void skip(int n) { for(int i = 0; i < n; i++) read(); }
};
class DatabaseVideo {
ICursor<Frame> getFrames() {}
ICursor<Scene> getScenes() {}
};
I then deleted the IVideo interface, and instead had concrete classes for input videos and database videos. This would allow me to simplify the FileDatabase::saveVideo logic, and removed the need for empty adapters.
The sequence matching algorithm could load scenes from an ICursor<Scene>, which could be implemented for both query videos and database videos, simplifying the the matcher.
Parallelization
Calculating the color histograms and sift descriptors for a video are independent, and the frame descriptors depend only on the sift descriptors. This means I was able to calculate the SIFT descriptors, color histograms, and frame descriptors in parallel, and write them to the database in parallel.
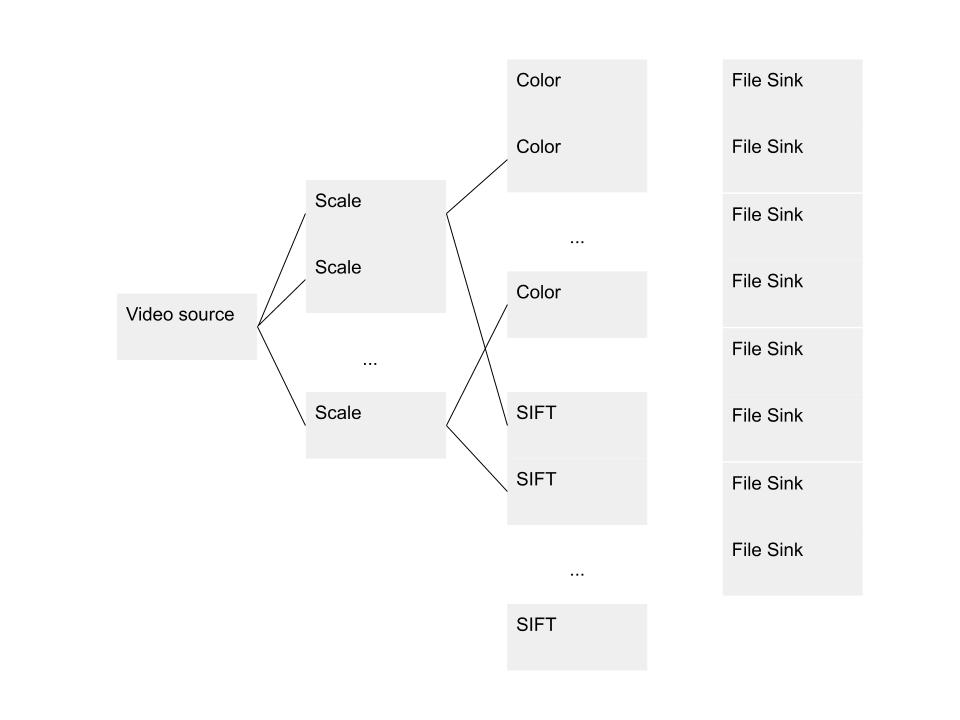
I split FileDatabase::saveVideo() into two functions, saveVideo(InputVideo) that runs the above parallel pipeline on a new video, and saveVideo(DatabaseVideo) that reprocesses a video in the database by running sequential pipeline stages.
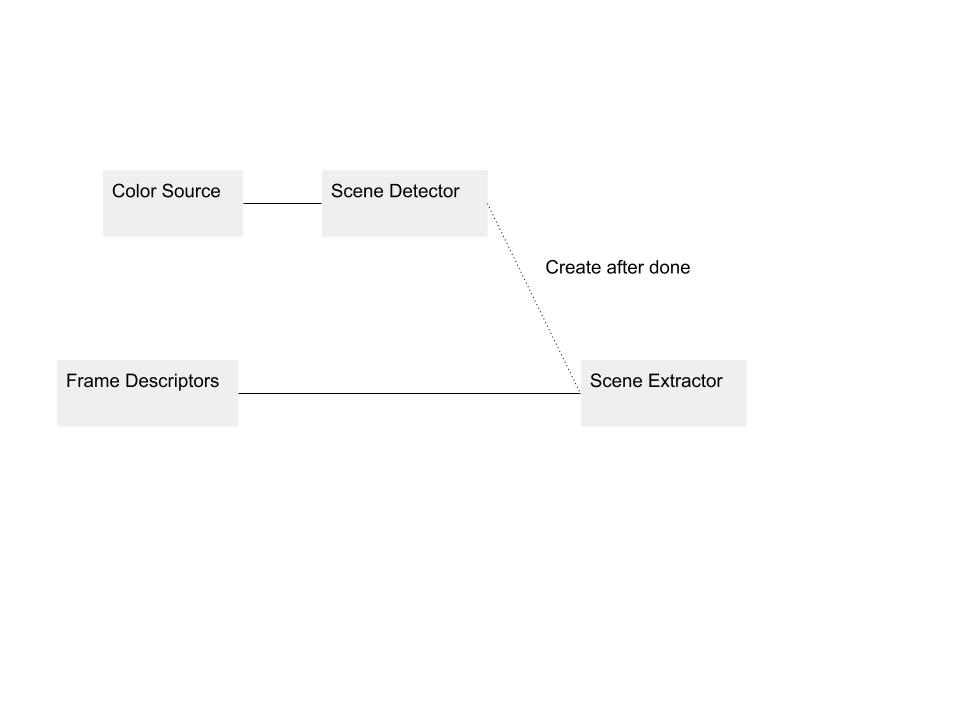
I used Intel Threading Building Blocks (TBB) to provide the functionality of this parallel pipeline. TBB requires functor objects or equivalent in each stage, so I created these in separate classes that were also used in my ICursor iterator implementations.
Video matching
I suggested that we use Smith-Waterman, an algortihm I had learned from my Natural Language Processing class, to compare sequences of videos. I made a templated version so we could use it to test any two sequences with an appropriate comparison function. This comparison function would return a discrete score for any pair of elements in the sequence.
For matching descriptor vectors we decided to find the cosine distance between the vectors and map [0.8, 1] as 3 and [0, 0.8) as -3. We used a gap penalty of 2 and extracted the top 3 alignments from our dynamic programming table.
Popular implementations of Smith-Waterman use SSE and vectorization to optimize their runtime. Since we used a generic implementation, these optimizations were not available to us.
I used google benchmark to run benchmarks of the Smith-Waterman implementation, and then used profiling to figure out where most of the time was being spent in the implementation. The longest part of our runtime was reconstructing the alignments, since each cell in the DP table stores a back pointer, we had to find the maximum element in the DP table for each alignment we returned. We also zeroed out the values of each alignment from the table to prevent returning overlapping alignments. I could not find a way to optimize this further.
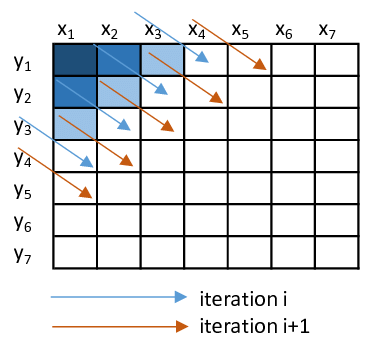
One optimization I was able to make was to use a wavefront method to parallelize the generation of the DP table. Running it through my benchmarks showed that I was getting 2x speedup from this method.