Synopsis
My friend Sergei and I attended SLOHacks 2018. We wanted to make the web more accessible by configuring different input devices for browsing the web. It should be possible for someone without the ability to use a mouse and keyboard, or touchscreen, to still be able to browse the internet.
Before the SLOHacks, we researched various methods for tracking the user’s eyes. We wanted something that would track the user’s eyes on a webpage, through their webcam, and click links or buttons on the browser through voice commands. We found that this was quite a hard problem, and required specialized hardware, or proprietary solutions we couldn’t use in a hackathon scenario.
We found that Google had cloud APIs for both facial recognition and speech to text, so we wanted to leverage these technologies in our application.
Implementation
- Selenium allows us to programmatically control a browser
- Google Cloud APIs for live speech recognition
- OpenCV tracks face and tries to detect deliberate head tilts
- Python script integrates all 3 elements
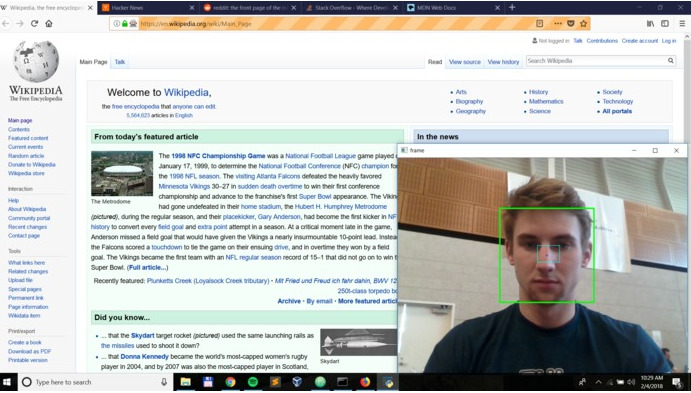
Face tracking
Scroll and tab switching is controlled by the user’s face. We originally wanted to use Google’s face recognition to get the pan and tilt angles of the user’s face, and then threshold these values for our gesture recognition. However, Google’s API had a latency of about 2 seconds so it was not possible to just use this for gesture recognition.
We used OpenCV and its builtin Haar cascade filter to detect the user’s face through the webcam. We map tilting the head up to scrolling up, head down for scrolling down, left for previous tab, and right for next tab. We detect head tilt by checking whether the center of the user’s face crosses any side of a rectangle of known dimensions around the center of their face. We found that the center of a user’s face was around their nose, so the name NoseGoes was chosen for our project.
I did a lot of work to make this gesture recognition usable. Originally we experimented with different dimensions for the threshold rectangle, but this still had the issue where that rectangle was centered around the position where their face was first detected. The original implementation forced the user to keep their head in a relatively fixed position, causing neck strain. Another issue we were having is that the output from the Haar Cascade was noisy, and we would have to use a large threshold rectangle to compensate. Having a large rectangle meant that the user would have to tilt their head more as there is a sinusoidal relation between head tilt and nose position projected on the camera plane, causing further neck strain.
I decided to filter the noise from OpenCV by applying an window average filter (or rectangular convolution) of the user’s head position. This reduced the amount of noise coming from the OpenCV signal, and allowed us to reduce the size of the threshold rectangle.
To allow the user to move their head without triggering a gesture, the threshold rectangle tracked the user’s position based on an expoential average of the head position. The exponential parameter was tuned so that tilting the head as a gesture control would trigger the threshold without causing the box to move out of position.
Voice controls
We used Google’s Speech-to-text cloud API to get the user’s speech so that we could recognize a number of voice commands for our demo. We would search for a keyword in the user’s speech, and take the next word spoken as the argument to the command. Some of the commands we implemented were:
- “Go back”: Go back in the browser history
- “Go forward”: Go forward in browser history
- “Search”: search for a sentence on google
- “Go to”: go to a website directly
Given more time we might have enabled “clicking” on links by using Selenium to scrape the current page for links and match that to speech input.
Demo
Sergei demos our solution